Introduction
Loading flat files can be a bit time consuming with the “normal” approach by creating an Infopackage and prepare the settings with field list. Also, in times of LSA++ and BW4/HANA the PSA are outdated. Therefore, we have created a solution for directly creating a field based ADSO based on a flat file and load the data within one program without too much preparation.
Program
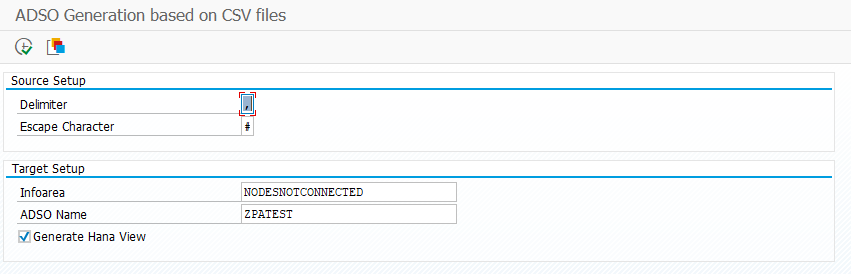
- Set delimiter and escape character according your file you want to upload.
- Set InfoArea and ADSO name
- Check Generate Hana View if you want to have an external Hana view generated.
First run of the Program:
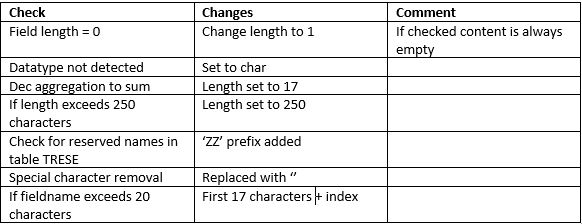
Within the first run of the program the csv will get analyzed, implying that the ADSO is not already existing. Headers will be determined but also the datatype and length of the column. Based on this detection and settings a field based ADSO will be created.
Please make sure to go over the detected datatypes and lengths. Length’s will be automatically increased by 20 percent of the longest entries. ID’s will be created as decimals, make sure to change if needed. After you have made the small adjustments you can run the program for the second time to write the csv file into your generated ADSO.
Second run of the Program:
In the second run the program will detect that the ADSO Name already exists in the system. The program will therefore try to write the data into your ADSO. The message “Data successfully written to ADSO [your ADSO] will appear after successfully uploading your CSV.
Analyze CSV:
- Extracts the header information (1 row must be set up with unique column names).
- Analyze length and type (simple check if char or dec).
- The datatypes are chosen as they allow direct reporting and a quick DQ setup (e.g. direct SAC Model on the generated Calculation View) -> Tick Checkbox for Generate Hana View. Also respecting the guidelines in the following note: https://launchpad.support.sap.com/#/notes/2185212
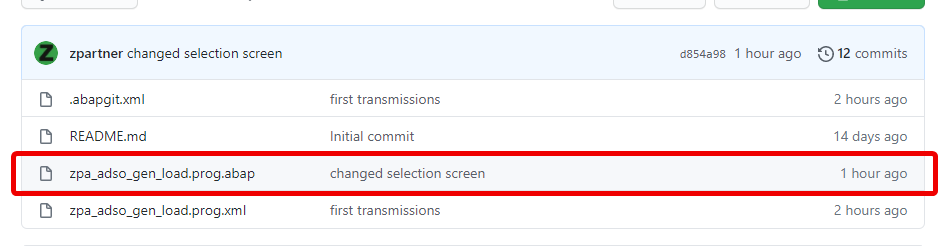
Github:
https://github.com/zpartner/adso_gen_load
Either synchronizing with github or copy and paste the coding into your own report:
Conclusion
With this little helper it becomes quite easy to get your local data into your BW system for Testing purposes or recurring manual uploads (execute program variant in process chain) and you can quickly build on top of your field based extraction layer.